实验任务简介
实验背景
本次实验需要利用 $MATLAB$ 和所学的图像处理相关知识,根据提供的书法字图片库,从中选择一张并查找与之相似的书法字图片。
实验环境
实验操作系统环境为 Windows 10 ,$MATLAB$ 版本为 R2021b 。
实验思路
实验大致分为以下几步:图片二值化预处理,图片细化预处理,图片特征值提取预处理和相似度计算及排序。
程序框架与技术细节
总体框架
程序大致框架为:main.m 是程序入口,为程序整体流程;PreProcessing.m 为预处理函数, Rosenfeld.m 为将二值图像细化的函数,剩余的函数为不同维度的特征值提取函数。程序运行流程图如下。

各模块功能介绍
main.m
main 函数主要包含以下过程:选择书法字图片文件夹路径,调用预处理函数对图片进行预处理,引导用户选择待匹配的书法字图片,计算该图片与图片库中的其他图片的相似度,提示输入匹配的结果数量 k ,排序输出前 k 张图像。大致运行过程如下图所示。

PreProcessing.m
PreProcessing 函数主要进行预处理,其中预处理分为以下几个部分:将图片缩放为 300 * 300 大小,调用系统函数将图片二值化并保存,调用 Rosenfeld 函数将二值图细化并保存,调用各特征值函数计算图片特征值并进行归一化处理,最后保存特征值。三个保存的作用在于避免多次调用程序进行匹配时重复预处理。
Rosenfeld.m
Rosenfeld 函数用于将二值图细化,采用了 Rosenfeld 细化算法进行处理,具体实现如下:
-
概念定义:
-
8-邻居:如果像素点 P 和像素点 Q 有公共顶点或公共边,则称 P 和 Q 互为 8-邻居。
-
八邻域表示法:对于一个像素点,我们用如下的方式对它和它的 8 个 8-邻居进行标号。

-
边界点:对于某一个前景像素点 p1 ,如果 p2 为背景像素点,则称 p1 为北部边界点。同理可得南部边界点、东部边界点、西部边界点的定义。
-
8-联通块:对于一个点集 P ,如果 P 满足以下性质,则称 P 为 8-联通块。
- P 中的所有像素点均为前景像素点。
- 对 P 中的任意两个点 $p_i$ 和$p_j$ , 存在一个像素点的序列 $p_i,\ … ,\ p_j$ ,使得序列中任意相邻的两个点都互为 8-邻居。
-
8-联通性:一个 8-联通块内的任意点之间具有 8-联通性。
-
8-simple 点:对于一个前景像素点 p1 ,如果将其值设为背景值后,它的 8 个 8-邻居的 8-联通性不改变,则称该点为 8-simple 点。
-
孤立点:如果一个前景像素点 p1 的 8 个 8-邻居均为背景像素点,则称该像素点为孤立点。
-
端点:如果一个前景像素点 p1 的 8 个 8-邻居中有且仅有 1 个前景像素点,则称该像素点为端点。
-
-
算法步骤:
- 扫描所有像素,如果像素是北部边界点,且是 8-simple 点,但不是孤立点或端点,删除该像素。
- 扫描所有像素,如果像素是南部边界点,且是 8-simple 点,但不是孤立点或端点,删除该像素。
- 扫描所有像素,如果像素是东部边界点,且是 8-simple 点,但不是孤立点或端点,删除该像素。
- 扫描所有像素,如果像素是西部边界点,且是 8-simple 点,但不是孤立点或端点,删除该像素。
- 重复执行上述步骤,直到没有像素点可以删除。
-
细化结果示例:


Histogram.m
Histogram 函数用于统计二值图像中前景像素点(即黑色像素点)的个数,也就是对二值图像进行直方图统计,并将前景像素点个数作为特征值的一维返回到 PreProcessing 中。
Contour.m
Contour 函数用于提取二值图像外轮廓并统计外轮廓总像素点数作为特征值的一位返回到 PreProcessing 中。提取外轮廓的算法:生成一个空白的外轮廓图矩阵,扫描待处理的二值图像中的每一个像素点,若它前景像素点,则将它的 8-邻居点中的背景像素点的对应坐标在外轮廓图中标记为前景像素点。核心部分代码如下:
|
|
轮廓提取结果示例如下:

OutArea.m
OutArea 函数用于提取汉字外围轮廓特征信息,提取过程如下:
- 将图像缩放为 296 * 296 大小。
- 对图像沿上下左右四个方向扫描。
- 对每一次扫描,将图像沿垂直扫描方向等分为 4 份。例如,从上到下扫描时,将图像从左至右等分。
- 对于等分的每一份,沿扫描方向,统计到第一次碰到汉字笔画位置的像素点数。
- 共进行 4 * 4 = 16 次统计,得到 16 个结果,作为 16 维特征值返回 PreProcessing。
扫描示例如下(从上到下方向,得到 4 维度的特征值):

HOG.m
HOG 函数用于计算图像的梯度信息,并整合到直方图中作为特征值返回。图像的梯度描述了图像颜色的变化方向及变化密度,而对于书法字二值图像而言,梯度反应了汉字轮廓边缘的方向信息。梯度提取过程如下:
- 将二值图像缩放为 64 * 64 大小。
- 利用梯度算子计算每一个像素点的梯度值:
- 水平边缘算子:$[-1, 0, 1]$
- 垂直边缘算子:$[-1, 0, 1]^T$
- 水平梯度幅值:$G_x(x, y) = I(x + 1, y) - I(x - 1, y)$
- 垂直梯度幅值:$G_y(x, y) = I(x, y + 1) - I(x, y - 1)$
- 梯度幅值:$G(x, y) = \sqrt{G_x(x, y)^2 + G_y(x, y)^2}$
- 梯度方向:$\theta(x, y) = arctan\frac{G_y(x, y)}{G_x(x, y)}$
- 将图像划分为 8 * 8 的单元格。
- 对每一个单元格,统计其中的像素点的梯度方向。由于二值图像的像素值只有 0 / 1 两种可能,故梯度方向只有 $0^\circ$ 、 $45^\circ$ 、 $90^\circ$ 、 $135^\circ$ 四种可能(将正负梯度视为相同),再将 0 作分母的情况作为一种可能,最终形成 5 个维度的直方图。统计直方图时,每计算一个像素点,直方图中增加的数量为其梯度幅值。
- 对所有的 8 * 8 个单元格执行统计,最终得到 8 * 8 * 5 = 320 维的特征值返回。
InnerFill.m
InnerFill函数用于统计汉字较粗糙的结构信息并作为特征值,提取过程如下:
- 内部点概念定义:对于任意一个背景像素点,若向它的上下左右四个方向扫描都能扫到前景像素点,则称这个像素点为汉字的“内部点”。
- 提取步骤:
- 将细化图像缩放为 296 * 296 大小。
- 对细化图的每一个点,计算其行方向和列方向上的前缀和,加快后续计算效率。
- 扫描细化图的每一个像素点,如果该点是背景像素点,则通过前缀和判断其上下左右四个方向是否都存在前景像素点,若存在,则该点为内部点,将其填充为前景色(即黑色)。
- 将图像划分为 4 * 4 = 16 个单元格,每个单元格大小为 74 * 74 。
- 统计每一个单元格内的前景像素点数,共得到 16 个值,作为 16 维特征值返回。
内部点填充示例如下:

InnerContour.m
InnerContour函数用于提取汉字内部的结构信息特征值,提取过程如下:
- 将细化图像缩放为 296 * 296 大小。
- 对图像沿上下左右四个方向扫描。
- 对每一次扫描,将图像沿垂直扫描方向等分为 4 份。例如,从上到下扫描时,将图像从左至右等分。
- 对于等分的每一份,沿扫描方向,统计到第一次碰到汉字笔画位置到第二次碰到笔画位置之间的像素点数。
- 共进行 4 * 4 = 16 次统计,得到 16 个结果,作为 16 维特征值返回。
扫描示例如下(从上到下方向,得到 4 维度的特征值):

Centroid.m
Centroid 函数用于计算汉字二值图像的质心位置,并将横纵坐标作为 2 维度的特征值返回。质心位置计算公式如下: $$ G_x = \sum_{i = 1}^r \sum_{j = 1}^c i \times I(i, j) \ G_y = \sum_{i = 1}^r \sum_{j = 1}^c j \times I(i, j) $$
程序运行示例
运行说明
打开 $MATLAB$ 后,操作步骤如下:
- 将 src 目录设为 $MATLAB$ 当前文件夹。
- 在 $MATLAB$ 命令行窗口输入
main运行程序。 - 程序提示输入 calligraphy 文件夹路径,按要求输入即可。
- 等待大约 10 分钟(视测试设备性能而定,仅第一次运行需要等待),预处理完成,弹出文件选择对话框,在 calligraphy_binary 目录下选择待匹配的书法字图片。
- 按提示输入匹配的结果数量。
- 等待程序计算相似度并排序输出结果。
运行结果示例
运行过程和结果示例如下:

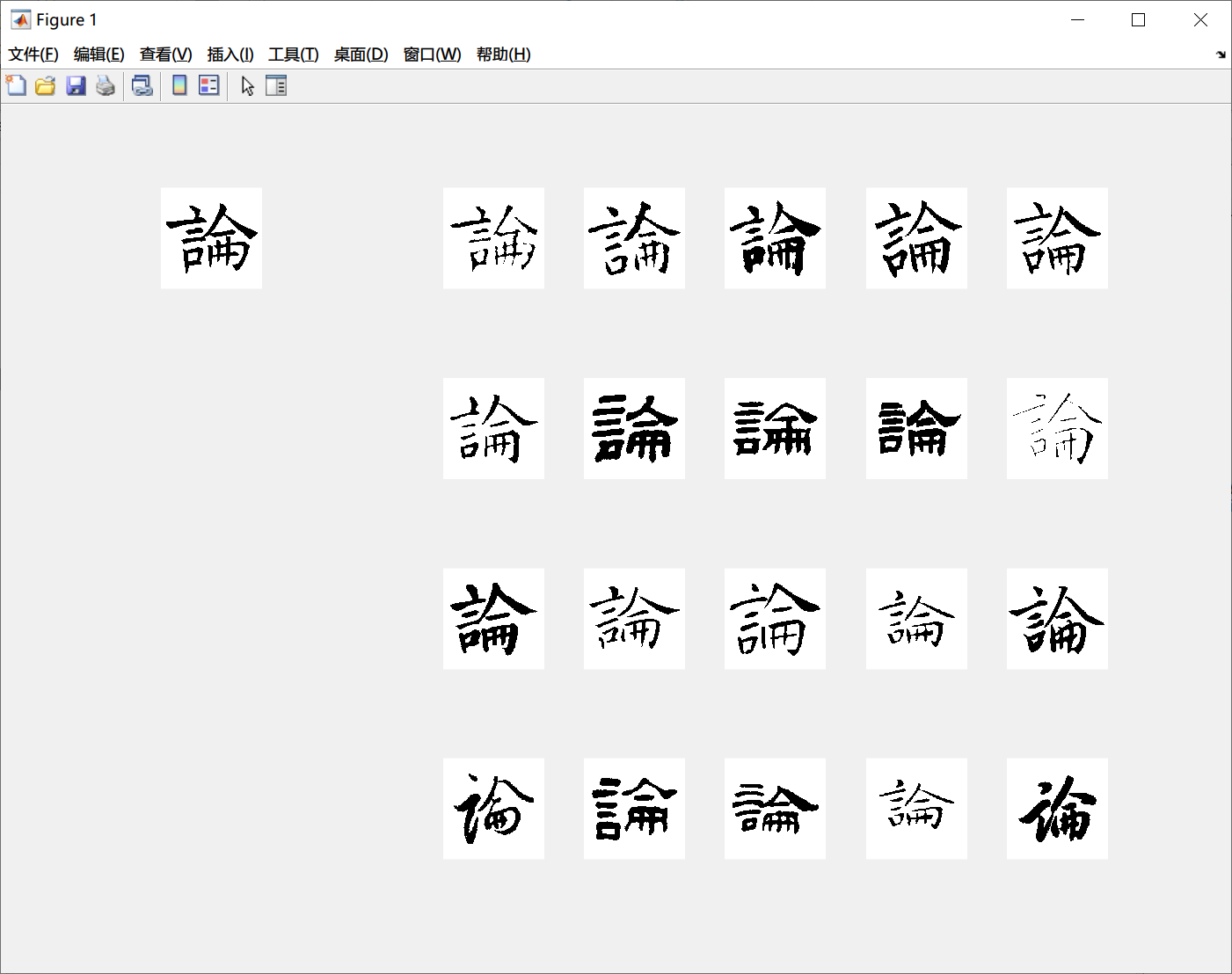
实验结果分析
实验结果展示
由于书法字图片库中图片数量较多,这里仅选择其中一小部分有代表性的图片进行匹配结果的展示。
| 匹配图片 | 汉字 | 字体 | 匹配结果 | 匹配准确率 |
|---|---|---|---|---|

|
论 | 楷书 | 
|
100% |

|
仰 | 楷书 | 
|
100% |

|
礼 | 隶书 | 
|
100% |

|
水 | 隶书 | 
|
100% |

|
物 | 篆书 | 
|
95% |

|
我 | 行书 | 
|
85% |

|
学 | 行书 | 
|
85% |

|
月 | 草书 | 
|
85% |

|
惟 | 草书 | 
|
75% |
结果分析
- 从上述结果及更多测试中的结果,可以比较明显地看到,楷书的匹配准确率最高,基本都可以维持在90%及以上,这主要是由于楷书通常字体比较端正,整体结构也较为统一,因此各项特征值在提取的过程中都比较接近,算出来的相似度就比较准确。
- 草书的识别准确率比较低,主要是由于草书的字体结构比较自由,不同的书法家在不同的场合可能写出来的草书字体相差也很大。对于人的视觉系统而言,在观察一个字的时候可能更注重字的笔画结构和笔画拓扑结构;而对于此次实验的程序而言,提取的更多是汉字在方框内的空间结构,因此对草书的匹配率就不高了。
算法对比
颜色直方图统计对象
在测试过程中,颜色直方图的统计对象是一个考虑的点。因为在预处理的过程中生成了二值图和细化图,所以测试的时候分别用 Histogram 函数对两个进行了对比。经过抽样测试,这两者的表现在匹配结果上完全一致。原因可能在于这些书法字的图片笔粗细较为一致。
质心统计对象
同样的,我们也对质心的计算对象进行了对比。结果与上述过程相同,原因应该也是类似的,当笔的粗细相似的时候,二值图和细化图的质心位置对图片相似度的影响很小。
上述两个算法对比的测试抽样结果如下:
分割子图数目
在许多特征值的提取过程中,都会将书法字图像分割为几个子图,以提高程序的鲁棒性。由于图片缩放大小为 300 * 300 , 笔者在最初设计的时候选择将子图分为 3 * 3 = 9 份。后来经过资料的查阅,发现大多数算法都选择将图片分割为 4 * 4 = 16 份。经过笔者的测试,确实分割为 16 份的匹配准确率更高,因此对于这些函数,在最开始的处理之前都会有将图片缩放到 296 * 296 大小这一步。
参考文献:
[1] PandasRan.汉字常用特征的提取方法详解[EB/OL](2016-07-24).
https://blog.csdn.net/jy02660221/article/details/52012543
[2] lambda.图像特征:方向梯度直方图 HOG[EB/OL](2020-03-22).
https://blog.csdn.net/Augurlee/article/details/105034336
[3] 程序员阿德.一文讲解方向梯度直方图(hog)[EB/OL](2022-05-31).
https://zhuanlan.zhihu.com/p/85829145
[3] 迈克老狼2012.OpenCV学习(16) 细化算法(4)[EB/OL](2013-09-17).
https://www.cnblogs.com/mikewolf2002/p/3327318.html
[4] Abeer George Ghuneim.Contour Tracing[EB/OL](2000).
[5] 海神之光.基于matlab SVM汉字识别[EB/OL](2022-05-29).